
데이터베이스를 다뤄본 사람이라면 인덱스라는 용어를 한번쯤은 들어봤을것이다. 쿼리를 계속 다루다보면 자연스럽게 인덱스라는 개념을 접하게 되는 것 같다. 내가 처음 인덱스를 접한건 대학교시절 실습 때 하나의 Query set을 돌려보면서였는데, 쿼리를 자세히 살펴보니 Create table 뒤에 Index를 설정하는 쿼리가 따라붙어있었다. 이게 뭔 역할을 하는건지는 모르겠지만 테이블 설정을 위해서 꼭 필요한건가보다, 하고 넘어갔던 것 같다.
지금은 Index가 뭐고, 왜 설정해야 하는지는 알지만 내가 과연 그래서 적절히 잘 활용하고 있는가?에 대한 질문을 스스로에게 해보게 된다. 그래서 간단하게 인덱스의 정의 및 필요한 시점, 현재 내가 조금 더 집중해야 하는 부분이 어떤 파트인지를 정리해보고자 한다.
인덱스(Index)란?
위키백과에서는 인덱스를 이렇게 정의한다.
데이터베이스 분야에 있어서 동작의 속도를 높여주는 자료 구조
나는 여기에서의 동작이 특히 select 쿼리와 연관이 깊다고 생각한다. 검색 효율도 높여줄 뿐 아니라 레코드에 대한 접근을 기본으로 하는 동작을 더욱 효율적으로 만들어준다. 어떻게보면 매순간 꼭 필요한 요소로 볼 수도 있겠지만 사실 인덱스는 테이블이 존재하는 곳마다 필요한 존재는 아니다. 테이블의 레코드 수에 따라 인덱스가 진가를 발휘하기도 하고, 별 쓰잘데기 없는 존재가 되기도 한다. (일반적으로 A few thousands row 이상의 테이블에 적용한다고 한다.)
인덱스를 붙여주는 작업을 하지 않으면 데이터베이스는 기본적으로 "Sequential scan" 방식으로 필요한 레코드를 찾는다. Sequential scan은 곧 Full table scan이다. 조건에 맞는 거 찾을 때 까지 첨부터 끝까지 찾겠다는 거다. 혹시 이게 정확히 뭔지 모른다 하더라도 말만들어도 골치가 아플것이다. 이럴 때 필요한게 인덱스겠지.
인덱스는 우리가 문서더미에 붙이는 색인같은 거다. 페이지가 많으면 많을수록 그 진가를 발휘한다. [페이지 수만 붙여놓은 1000페이지짜리 백과사전 vs. abc 순서대로 색인을 붙여놓은 1000페이지짜리 백과사전]? 나는 두말 않고 후자를 선택한다. 컴퓨터에게든 사람에게든 노동의 고됨 기준을 떠나서 어쨌든 노가다는 힘든거야..
PostgreSQL은 관계형 데이터베이스이면서 공간데이터를 취급하는 데이터베이스이기 때문에 공간 인덱스에 대한 내용을 빼놓을 수 없다. PostgreSQL에서는 여러 인덱스 유형을 지원하고 있다. 그 중 몇가지 인덱스에 대해서만 간단하게 정리하고 넘어가고자 한다.
- B-Tree Index : 일정 기준에 의해 정렬될 수 있는 데이터에 대해서 Comparison operation을 처리하기에 적합한 인덱스. 특히 PostgreSQL의 쿼리 플래너는 인덱싱이 적용된 column에 대해 비교연산자를 사용할 때마다 B-Tree 인덱스 사용을 고려한다. 공간정보 데이터의 경우 공간채움곡선(space-filling curve), Z-order curve, 힐베르트 곡선(Hilbert curve)에 의거하여 정렬할 수 있다.
- R-Tree Index : PostgreSQL에서 8.1버전 이후 찾아볼 수 없게 됐다. GiST index와 비교하여 성능 차이를 뚜렷하게 알 수 없어서 지원 종료한 것으로 보인다.
- GiST : Generalized Search Trees의 약어. 단일 종류의 인덱스가 아니라 다양한 인덱싱 전략을 구현할 수 있는 인프라. GIS 데이터를 포함한 넓은 범주의 데이터 타입에 적용 가능하며, 2차원 공간데이터 유형에 대한 연산자 처리 클래스가 포함되어 있다. GiST 인덱스는 아래와 쿼리와 같은 "Nearest-neighbor" 검색을 최적화 할 수도 있다.
SELECT * FROM places ORDER BY location <-> point '(101,456)' LIMIT 10;Query plan으로 cost를 비교해보자
내 주 사용 DB는 PostgreSQL이다. SQLD 자격증 대비 때문에 공부할 때 Oracle과 SQL Server의 언어가 약간의 차이가 있다는 건 알게되었지만 사실 작업 스콥이 넓지 않고 데이터 조회, 삽입, 업데이트 등의 작업에 있어서는 DBMS 종류에 크게 제약이 없다. PostgreSQL은 Oracle 언어 기반이다.
PostgreSQL에서는 explain으로 쿼리플랜을 실행할 수 있다. 예제 테이블을 신설해서 index를 부여한 테이블과 그렇지 않은 테이블의 cost 결과를 비교해보는게 좋겠다. 예제 테이블은 서울 행정구역 shape파일이고, 레코드 10,506줄짜리 규모이다.
1-1. Select Query(No join, index O)
-- select query with comparison operators(with indexing)
explain
select count(*) from road_link2
where st_length(geom) > 700
1-2. Select Query(No join, No index)
-- select query with comparison operators(no indexing)
explain
select * from road_link2_noindex
where st_length(geom) > 700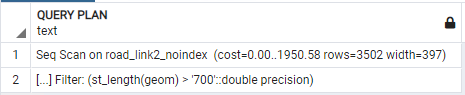
상기 1-1, 1-2를 보면 Index가 있고 없고의 차이는 없어보인다. 지금은 단순연산이지만 셀프조인하여 공간연산을 수행하거나 레코드 수가 대규모이거나 조금 더 쿼리가 복잡해지면 그 차이를 분명하게 알 수 있다. 아래 쿼리를 보면 그 차이를 명확히 알 수 있다.
2-1. Select Query(Join, Index O)
-- select query with comparison operators(using join, indexing)
explain
select road_with_idx.*
from road_link2 road_with_idx
, admin_emd ad
where st_intersects(road_with_idx.geom, ad.geom)
and ad.sgg_nm='종로구'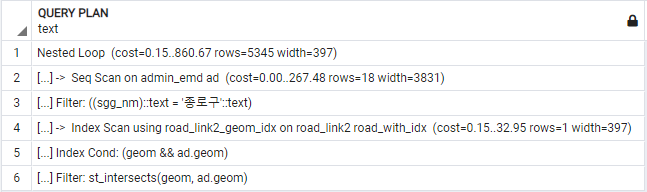
2-2 Select Query(Join, No index)
-- select query with comparison operators(using join, no indexing)
explain
select road_with_no_idx.*
from road_link2_noindex road_with_no_idx
, admin_emd ad
where st_intersects(road_with_no_idx.geom, ad.geom)
and ad.sgg_nm='종로구'
최종 수행에 소요된 비용에서 엄청난 차이를 보인다. 여기에서 Join을 수행한 테이블은 admin_emd(서울시 행정구역) 테이블로서, 쿼리플랜에서도 볼 수 있듯이 Geometry colomn에 Index를 부여한 테이블이다. 두 테이블 중 한 테이블에만 인덱싱이 되어있다면 다른 한쪽 테이블은 Full scan을 해야할 것이다.
다음에서 인덱스를 각각 다른 종류로 부여하고 cost를 비교해봐야겠다. 쿼리플랜을 보는 방법도 정리해두면 좋을 것 같다.
'기술공부 > DB' 카테고리의 다른 글
| [PostgreSQL] Insert 쿼리에서 Serial 컬럼 값 삽입하기 (0) | 2023.08.22 |
|---|---|
| [PostgreSQL] serial column의 start number를 재설정하는 방법 (0) | 2023.02.27 |
| [PostgreSQL] SQLite로의 Migration 기록(1) (0) | 2022.03.24 |